前言
本项目所爬取的数据为当当网站的商品信息以及商品的评论信息,并分别存储到数据库的商品信息表和评论信息表两个表中。
本项目通过使用Scrapy框架的CrawlSpider类,对当当全网商品信息进行爬取并将信息保存至mysql数据库,当当网反爬措施是对IP访问频率的限制,所以本项目使用了中间件scrapy-rotating-proxies来管控IP代理池,有关代理ip的爬取请见我的另一篇博文。
CrawlSpider是Spider的派生类,Spider类的设计原则是只爬取start_url列表中的网页,而CrawlSpider类通过定义一些规则(rule)来跟进所爬取网页中的link,从爬取的网页中获取link并继续爬取。
Github地址: https://github.com/RunningGump/crawl_dangdang
依赖
- scrapy 1.5.0
- python3.6
- mysql 5.7.24
- pymysql 库
- scrapy-rotating-proxies 库
- fake-useragent 库
创建项目
首先,我们需要创建一个Scrapy项目,在shell中使用scrapy startproject命令:
1 | $ scrapy startproject Dangdang |
创建好一个名为Dangdang的项目后,接下来,你进入新建的项目目录:
1 | $ cd Dangdang |
然后,使用scrapy genspider -t <template> <name> <domain>创建一个spider:
1 | $ scrapy genspider -t crawl dd dangdang.com |
此时,你通过cd ..返回上级目录,使用tree命令查看项目目录下的文件,显示如下:
1 | $ cd .. |
到此为止,我们的项目就创建成功了。
rules
在rules中包含一个或多个Rule对象,每个Rule对爬取网站的动作设置了爬取规则。
参数介绍:
link_extractor:是一个Link Extractor对象,用于定义需要提取的链接。
callback: 回调函数,对link_extractor获得的链接进行处理与解析。
注意事项:当编写爬虫规则时,避免使用parse作为回调函数。由于CrawlSpider使用parse方法来实现其逻辑,如果覆盖了 parse方法,crawl spider将会运行失败。
follow:是一个布尔(boolean)值,指定了根据规则从response提取的链接是否需要跟进。 如果callback为None,follow 默认设置为True ,否则默认为False
process_links:指定该spider中哪个的函数将会被调用,从link_extractor中获取到链接列表时将会调用该函数。该方法主要用来过滤链接。
process_request:指定该spider中哪个的函数将会被调用, 该规则提取到每个request时都会调用该函数。 (用来过滤request)
LinkExtrator
参数介绍:
allow:满足括号中“正则表达式”的值会被提取,如果为空,则全部匹配。
deny:与这个正则表达式(或正则表达式列表)匹配的URL不提取。
allow_domains:会被提取的链接的域名。
deny_domains:不会被提取链接的域名。
restrict_xpaths:使用Xpath表达式与allow共同作用提取出同时符合对应Xpath表达式和正则表达式的链接;
项目代码
编写item.py文件
1 | # -*- coding: utf-8 -*- |
编写pipeline.py文件
需提前创建好数据库,本项目创建的数据库名字为dd,并创建了两个数据表goods,comments。
1 | # -*- coding: utf-8 -*- |
编写middlewares.py
本项目添加了RandomUserAgentMiddleWare中间件,用来随机更换UserAgent。在middlewares.py文件的最后面添加如下中间件:
1 | from fake_useragent import UserAgent |
修改settings.py 文件
1 | BOT_NAME = 'Dangdang' |
spider文件(dd.py)编写
1 | # -*- coding: utf-8 -*- |
建立数据库
本项目使用的是mysql数据库,创建数据库的名字为dd,且创建了两个数据表分别为goods和comments,这两个表的结构如下:
goods表中的字段:
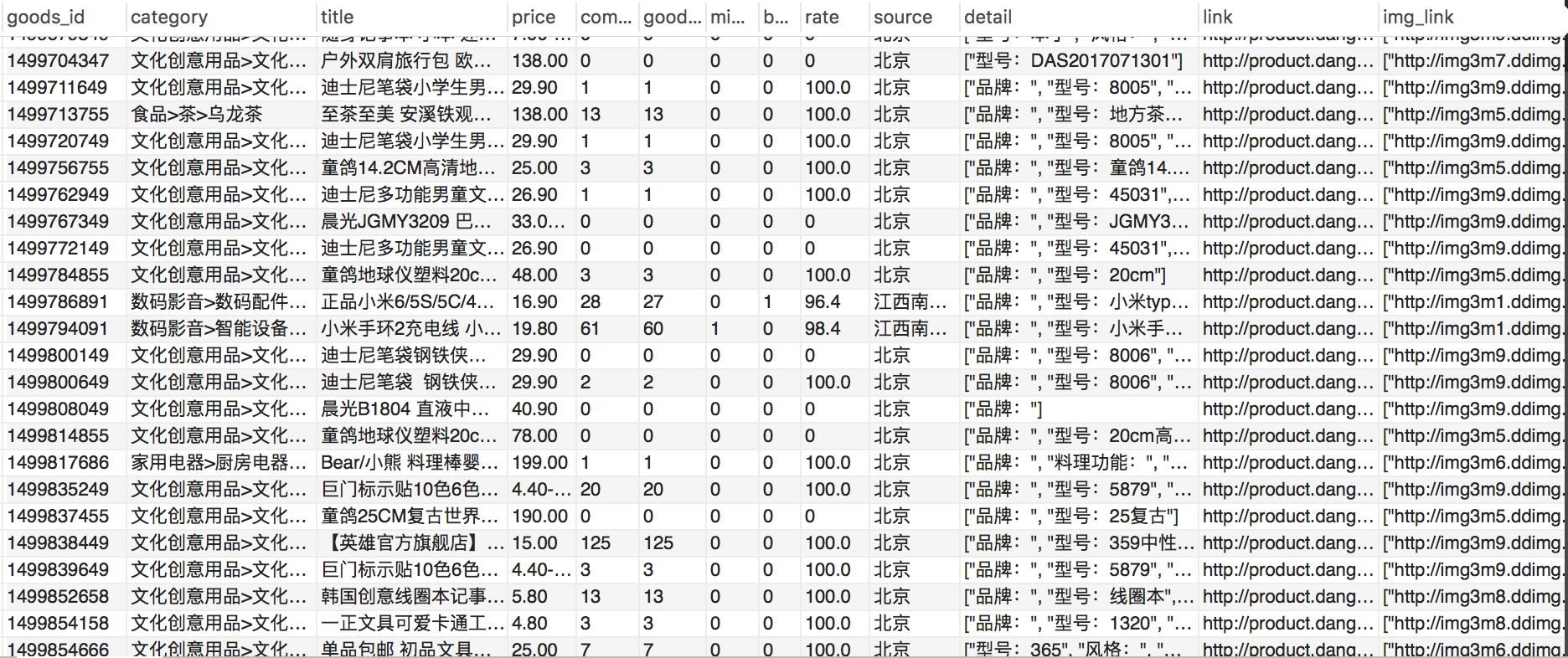
goods_id,category,title,price,comment_num,good_comment_num,mid_comment_num,bad_comment_num,rate,source,detail, link,img_link。分别代表商品id(主键)、商品类别、商品名称、商品价格、评论数量、好评数、中评数、差评数、好评率、商品来源、商品详情、商品连接(unique)、商品图片连接。
comments表中的字段:
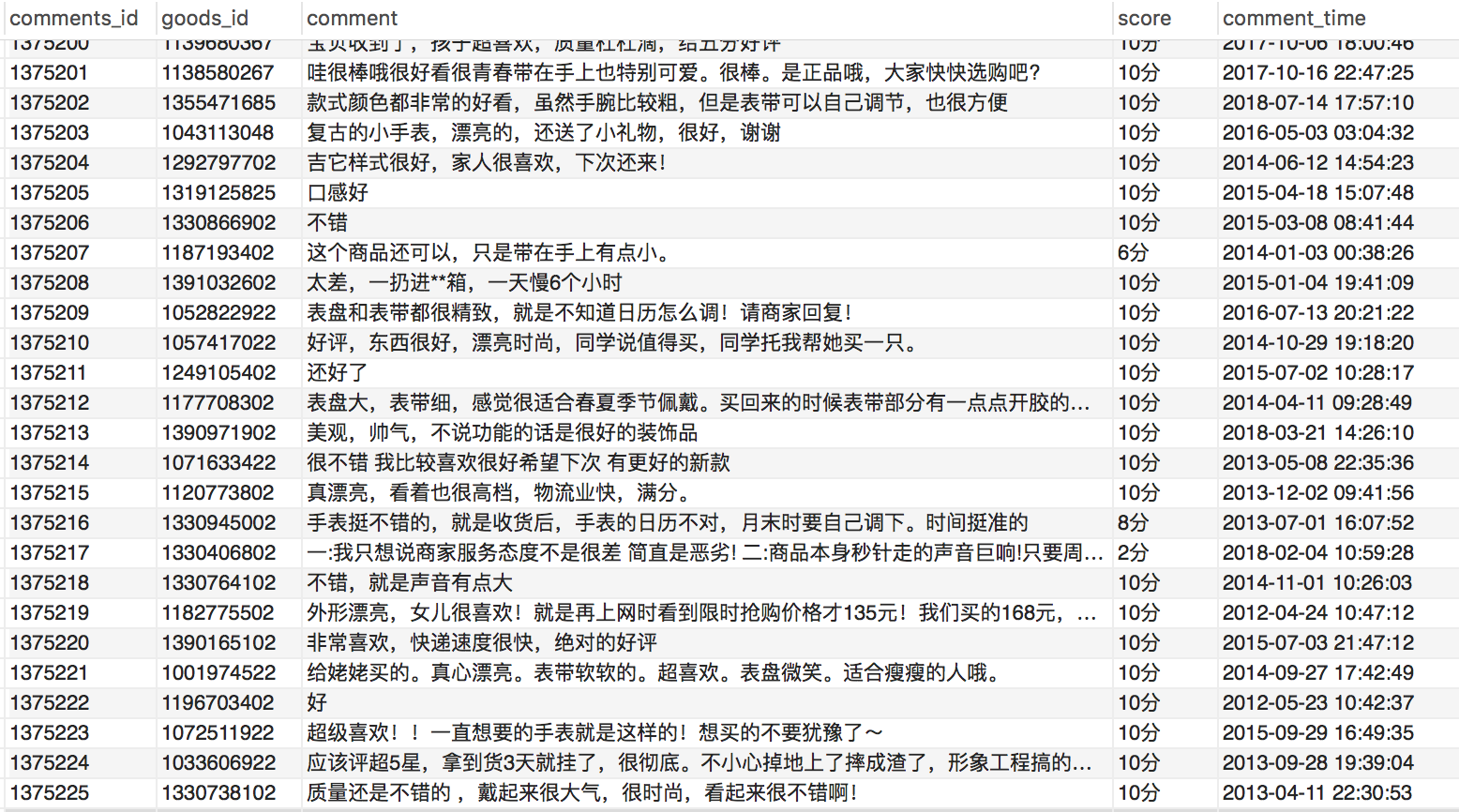
comments_id,goods_id,comment,score,comment_time。分别代表评论id(主键)、商品id、评论、商品评分、评论时间。
关于创建数据库/表的操作这里不再赘述,请自行百度。
使用方法
以上步骤操作完成后,在命令行中执行以下命令开始爬取:
1 | $ scrapy crawl dd |
结果展示
共爬取了214673条商品信息,和1375225条评论信息。(这并不是当当全部商品信息哦,我仅爬取了一部分)
商品信息表:
评论信息表: