前言
和同学一起参加这个比赛,由于报名比较晚了加之第一次参加这种数据分析的比赛经验欠缺,导致最终取得的成绩不是很好。不过,在这次比赛中的确收获了很多,使我对数据分析的整个流程有了更清楚的认识。
比赛已经结束后,对这个比赛做一个总结,以及对代码作出改进。改进后的模型使得预测结果在A榜达到了第3名。
数据集和代码见GitHub
赛题
本次比赛数据为某地4个月的房屋租赁价格以及房屋的基本信息,官方对数据进行了脱敏处理。
参赛选手需要利用数据集中的房屋信息和月租金训练模型,利用测试集中的房屋信息对测试数据集中的房屋的月租金进行预测。数据集分为两组,分别是训练集和测试集。训练集为前3个月采集的数据,共196539条。测试集为第4个月采集的数据,相对于训练集,增加了“id”字段,为房屋的唯一id,且无‘’月租金‘’字段,其他字段与训练集相同,共56279条。
评价指标是RMSE(均方根误差),是回归算法的常用评价指标。
训练集所含字段如下:
| 字段名 | 说明 |
|---|---|
| 时间 | 房屋信息采集的时间 |
| 小区名 | 房屋所在小区,脱敏处理 |
| 小区房屋出租数量 | 小区房屋出租数量,脱敏处理,保留大小关系 |
| 楼层 | 楼层高、中、低,脱敏处理 |
| 总层数 | 房屋所在建筑的总楼层数,脱敏处理 |
| 房屋面积 | 房屋面积,脱敏处理 |
| 房屋朝向 | 房屋朝向 |
| 居住状态 | 居住状态,表示是否已出租或居住中,脱敏处理 |
| 卧室数量 | 卧室的数量 |
| 厅的数量 | 厅的数量 |
| 卫的数量 | 卫的数量 |
| 出租方式 | 表示是否整租,脱敏处理 |
| 区 | 房屋所在的区级行政单位,脱敏处理 |
| 位置 | 小区所在的商圈位置,脱敏处理 |
| 地铁线路 | 数字表示第几条线路,脱敏处理 |
| 地铁站点 | 房屋临近的地铁站,脱敏处理 |
| 距离 | 房屋距地铁站距离,脱敏处理 |
| 装修情况 | 房屋的装修档次,脱敏处理 |
| 月租金 | 月租金、标签值、脱敏处理 |
分析
本文的讲解主要从以下几个方面展开:数据清洗、特征构建、模型训练、模型融合。通过参加这次比赛,我认识到了特征工程在整个数据分析过程占据着举足轻重的地位,此处只列出能够提升模型性能的特征,其他测试特征见我的GitHub。
数据清洗
画出房屋面积与月租金关系的散点图如下:
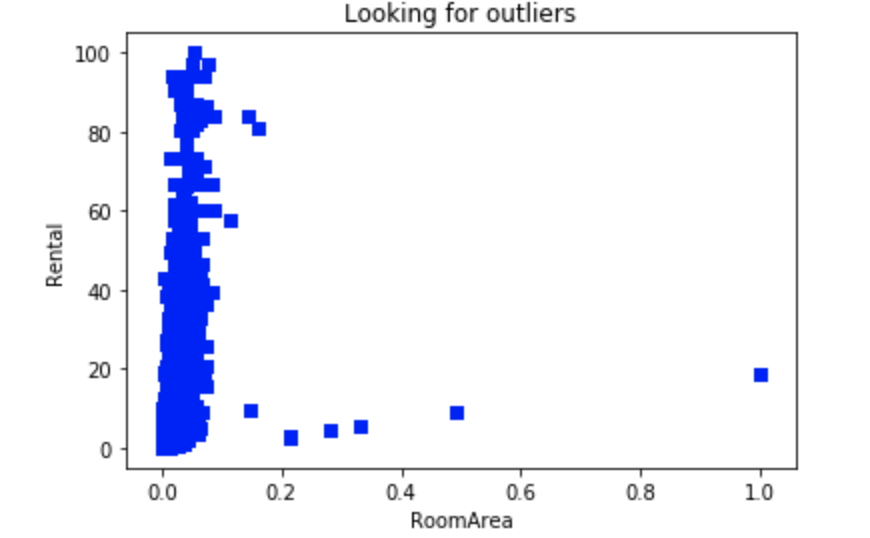
可以看到,房屋面积大于0.1的样本点属于异常值,将异常值去除。
1 | # 异常值清洗,上分 |
异常值清除后,画出房屋面积与月租金关系的散点图如下:
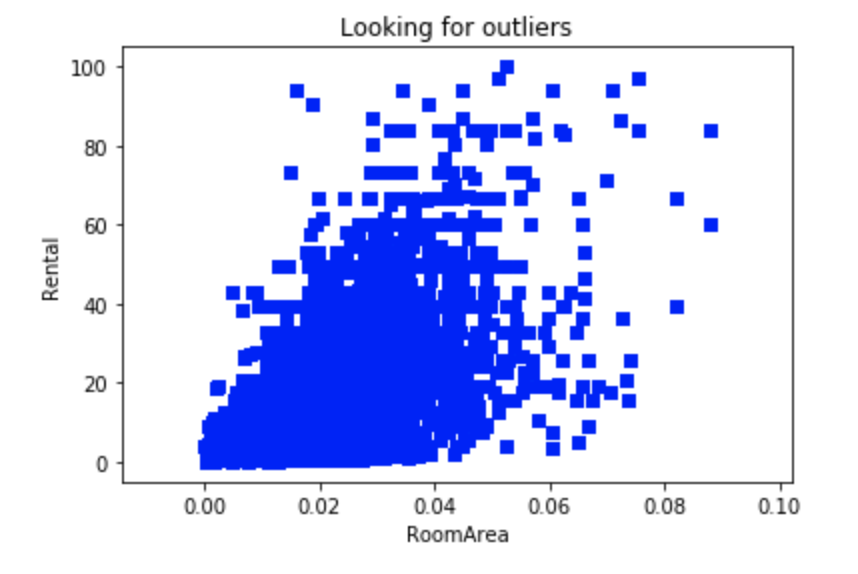
经过测试,去除异常值能够提升模型性能。
特征构造
我特征构造的思路是先根据常识来构造特征,比如:卧室&厅&卫总的房间数、卧室面积、厅的面积、卫的面积、房间相对高度等。然后,就是使用常用的套路来构造特征,比如:对类别型特征进行LabelEncoder编码、多个特征的线性组合、比例特征等等。
将使用原始特征求得的RMSE作为baseline,通过比较加入新构造特征后的RMSE与baseline的大小来筛选出有用的构造特征。
根据常识构造特征
所谓根据常识构造特征就是我们根据现有的知识推断出哪些特征与月租金的相关性强。
1 | # 总房间数、单个房间的平均面积、卧室面积、厅的面积、卫的面积 |
根据套路构造特征
对类别型或者离散型数据进行编码(如LabelEncoder编码、one-hot编码)、比例特征、特征的线性组合等等。
1 | # 对房屋朝向进行LabelEncoder |
模型训练
我采用的是XGBoost和LightGBM两个模型进行训练的,两个模型所使用的特征基本一致,最后XGBoost单模线上分数1.84,LightGBM单模先线上分数1.88。模型调参可以用Scikit-learn中的sklearn.model_selection.GridSearchCV
函数(模型调参我没有花太多时间,读者有兴趣可以自行调参)。这里直接列出我两个模型的参数:
1 | # xgb模型参数 |
模型融合
我这里采用的XGBoost和LightGBM两个模型加权融合,通过不断调试二者的比例,来提升模型性能。
1 | # -*- coding: utf-8 -*- |
最终,模型融合后的线上分数为1.82,总排名第三。可见,模型融合是可以提升模型预测效果的。
总结
模型训练仅仅会在一定程度上提升模型的性能,而特征工程决定了模型的上限,挖掘和目标值相关性强的特征是决胜的关键。
基于树的算法在处理变量时,并不是基于向量空间来度量的,数值只是个类别符号,即没有偏序关系,所以可以不用进行独热编码。
基于树的算法是不需要进行特征的归一化。
基于树的算法不擅长捕捉不同特征之间的相关性。
LightGBM和XGBoost都能将NaN作为数据的一部分进行学习,所以可以不处理缺失值。
将题目给的训练集分出一部分作为测试集后的训练效果没有全部将训练集用作训练的线上成绩效果好。